Does Minority Case Sampling Improve Performance with Imbalanced Outcomes in Psychological Research?
DOI:
https://doi.org/10.35566/jbds/v2n1/p3Keywords:
Imbalanced data, Sampling strategies, Machine learningAbstract
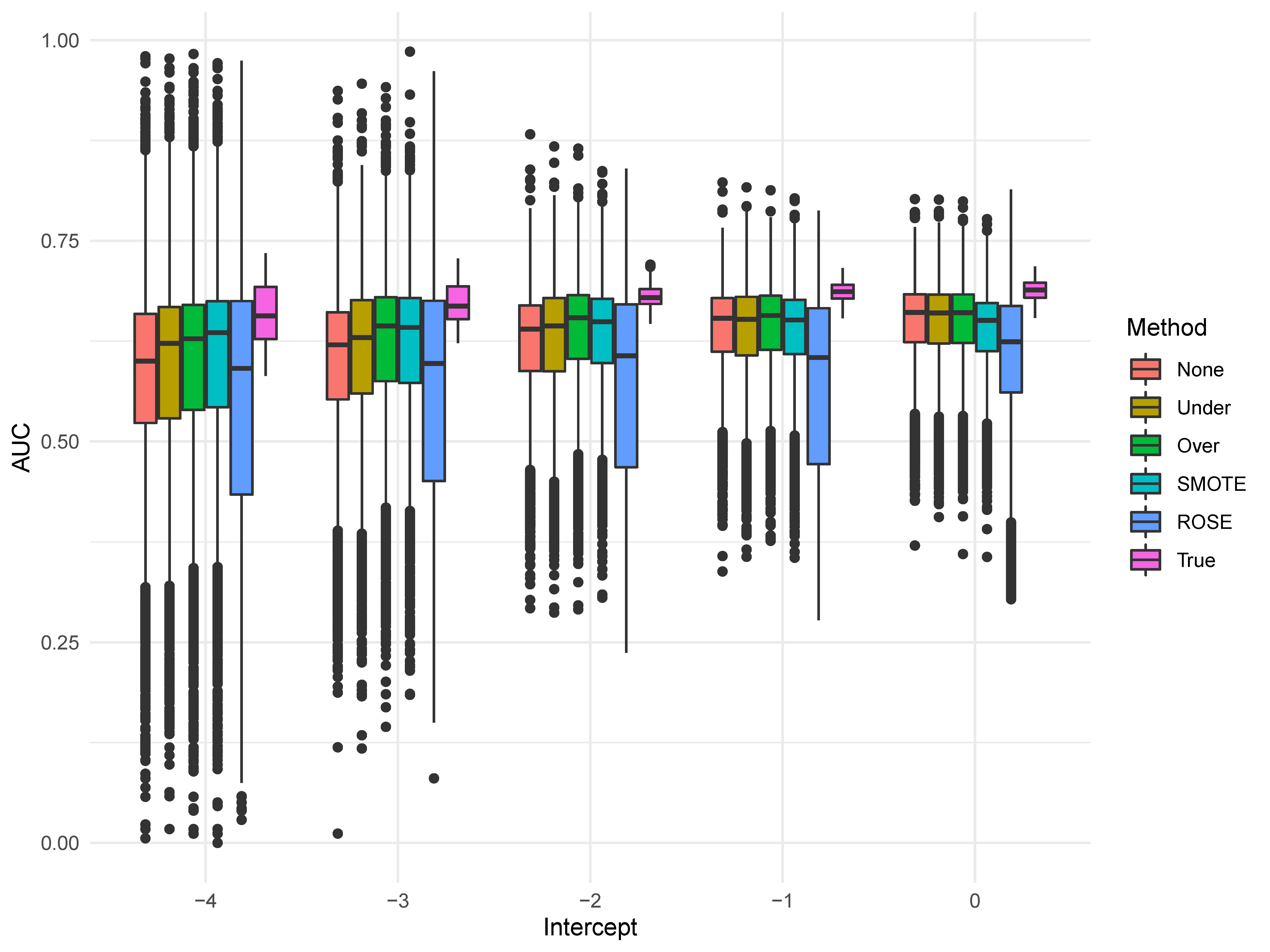
In psychological research, class imbalance in binary outcome variables is a common occurrence, particularly in clinical variables (e.g., suicide outcomes). Class imbalance can present a number of difficulties for inference and prediction, prompting the development of a number of strategies that perform data augmentation through random sampling from just the positive cases, or from both the positive and negative cases. Through evaluation in benchmark datasets from computer science, these methods have shown marked improvements in predictive performance when the outcome is imbalanced. However, questions remain regarding generalizability to psychological data. To study this, we implemented a simulation study that tests a number of popular sampling strategies implemented in easy-to-use software, as well as in an empirical example focusing on the prediction of suicidal thoughts. In general, we found that while one sampling strategy demonstrated far worse performance even in comparison to no sampling, the other sampling methods performed similarly, evidencing slight improvements over no sampling. Further, we evaluated the sampling strategies across different forms of cross-validation, model fit metrics, and machine learning algorithms.